线性分类
本文共 607 字,大约阅读时间需要 2 分钟。
1,基本概念
在机器学习领域,分类的目标是指将具有相似特征的对象聚集。而一个线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。对象的特征通常被描述为特征值,而在向量中则描述为特征向量。2,线性分类表达式
线性分类器用作图像分类主要有两部分组成:一个是假设函数, 它是原始图像数据到类别的映射。另一个是损失函数,该方法可转化为一个最优化问题,在最优化过程中,将通过更新假设函数的参数值来最小化损失函数值。
 x为数据(将三维矩阵转化为一维矩阵(列向量)),W为一系列权重参数(反映了对应数据对结果的影响),f(x,W)为每个类别的得分值(得分值高的类别为当前输入的类别),b为偏置项。
x为数据(将三维矩阵转化为一维矩阵(列向量)),W为一系列权重参数(反映了对应数据对结果的影响),f(x,W)为每个类别的得分值(得分值高的类别为当前输入的类别),b为偏置项。  利用权重参数和数据的线性组合,完成线性分类:
利用权重参数和数据的线性组合,完成线性分类:  3,损失函数
3,损失函数 一个例子(利用简单的标准评价当前的损失):
 sj代表错误的得分值,syi代表正确的得分值,1为错误容忍度,损失函数值较大表示分类效果不好。
sj代表错误的得分值,syi代表正确的得分值,1为错误容忍度,损失函数值较大表示分类效果不好。
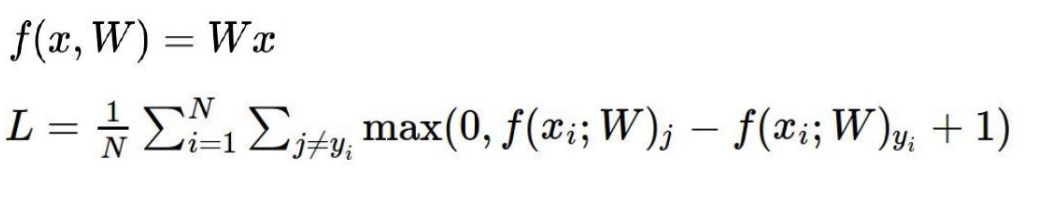 对于相同的数据,不同的模型,得到的得分值可能相同,如对于上式如果有以下两个模型:
对于相同的数据,不同的模型,得到的得分值可能相同,如对于上式如果有以下两个模型:  可以计算得到f(x,w)=1。而对于1号模型只关注局部值易产生过拟合现象。为了解决上述问题,引入正则化惩罚项。
可以计算得到f(x,w)=1。而对于1号模型只关注局部值易产生过拟合现象。为了解决上述问题,引入正则化惩罚项。 4,正则化惩罚项
在原有的损失函数的基础上加上正则化惩罚项:
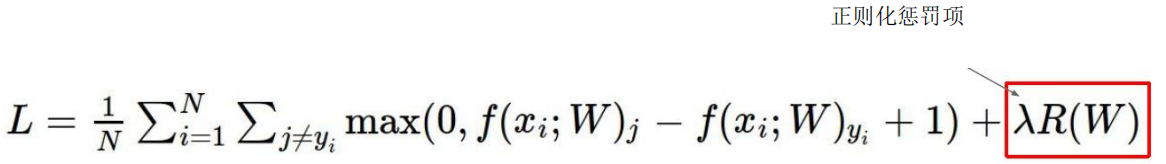 对于L2正则化惩罚项:
对于L2正则化惩罚项: 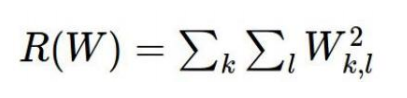 通过惩罚项的计算可知,对于2号模型的惩罚较小,即认为2号模型较好
通过惩罚项的计算可知,对于2号模型的惩罚较小,即认为2号模型较好 转载地址:http://gahwi.baihongyu.com/
你可能感兴趣的文章
如何添加一个提醒
查看>>
Cosmos 关机情况下来闹钟后增加是否开机选择功能
查看>>
日历的提醒内容可以根据需要修改
查看>>
如何使USSR编辑界面默认输入法为123
查看>>
手机中嵌入默认的快速拨号号码
查看>>
Call Setting中的Line Switch功能作用
查看>>
GPS数据解析
查看>>
The top 6 programming languages for IoT projects
查看>>
67 open source tools and resources for IoT
查看>>
蓝牙低功耗(BLE)应用领域
查看>>
nRF51822低功耗睡眠函数应用
查看>>
Android 语言码_国家码
查看>>
从iphone和android应用来看公司
查看>>
android 修改代码怎样编译
查看>>
领导者如何增强说服力
查看>>
比金钱更好的十样东西
查看>>
凡事必定不少于三个以上的解决方法
查看>>
带团队的点滴心经
查看>>
五种力量让你如虎添翼
查看>>
你害怕创新吗
查看>>